

Introduction to NLP
1.1 What is Natural Language Processing?
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and humans through natural language. The main goal of NLP is to enable computers to understand, interpret, and generate human language in a way that is both meaningful and useful. NLP encompasses a wide range of techniques and methods for processing text and speech data, including tokenization, parsing, sentiment analysis, and machine translation.
History of NLP
The history of Natural Language Processing (NLP) is a fascinating journey through the development of computational methods to understand, interpret, and generate human language. NLP has evolved over the decades, with its roots dating back to the early days of artificial intelligence and computer science. Here is a brief overview of the history of NLP:
- 1950s: The foundations of NLP were laid when Alan Turing proposed the Turing Test in his 1950 paper “Computing Machinery and Intelligence.” This test aimed to determine a machine’s ability to exhibit intelligent behavior indistinguishable from that of a human.
- 1960s: The first NLP systems were created during this period. ELIZA, developed by Joseph Weizenbaum at MIT in 1964, was one of the earliest examples of a chatbot that could mimic human-like conversations. In 1969, Roger Schank and Robert Abelson introduced the concept of “scripts” to represent real-world knowledge in AI systems.
- 1970s: Researchers started focusing on rule-based approaches to NLP. The development of the LUNAR system by William A. Woods in 1973, which could answer questions about moon rock samples, marked an important milestone in the field. This decade also saw the birth of the field of computational linguistics.
- 1980s: The focus shifted to statistical methods and machine learning techniques for NLP. The introduction of the Hidden Markov Model (HMM) in speech recognition and the development of probabilistic context-free grammars significantly advanced the field.
- 1990s: The rise of the internet led to the availability of massive amounts of textual data, which fueled the development of data-driven NLP methods. During this time, IBM’s Watson system, capable of natural language understanding, was developed, and the first large-scale statistical machine translation systems emerged.
- 2000s: The advent of more sophisticated machine learning techniques, such as Support Vector Machines (SVM) and Maximum Entropy models, further pushed the boundaries of NLP. In addition, the launch of the Google search engine and its emphasis on natural language understanding had a significant impact on the field.
- 2010s: Deep learning techniques, particularly neural networks and word embeddings like Word2Vec and GloVe, revolutionized NLP. The development of attention mechanisms and transformer architectures led to the creation of state-of-the-art models like BERT, GPT, and T5, which achieved human-like performance on various NLP tasks.
Throughout its history, NLP has evolved and adapted to the latest advances in computer science, artificial intelligence, and linguistics. As technology continues to progress, NLP will undoubtedly continue to play a crucial role in our increasingly digital and interconnected world.
A walkthrough of recent developments in NLP
From 2010 to 2021, the field of Natural Language Processing (NLP) experienced rapid advancements, primarily driven by the adoption of deep learning techniques. Here is an overview of some of the key developments during this period:
- Word Embeddings (2013): Word embeddings, such as Word2Vec and GloVe, were introduced as a method to represent words in a continuous vector space. These embeddings capture semantic and syntactic relationships between words and dramatically improved performance in various NLP tasks.
- Sequence-to-Sequence Models (2014): The seq2seq model, a deep learning approach using encoder-decoder architectures with recurrent neural networks (RNNs), was introduced for tasks like machine translation, summarization, and dialogue systems. These models made it possible to map input sequences to output sequences with varying lengths.
- Attention Mechanisms (2015): The attention mechanism was proposed as a way to address the limitations of fixed-length context vectors in seq2seq models. Attention allows the model to “focus” on different parts of the input sequence when generating the output, resulting in significant improvements in performance, particularly for tasks like machine translation.
- Transformer Architectures (2017): The Transformer architecture, introduced in the paper “Attention is All You Need,” eliminated the need for RNNs and instead relied solely on self-attention mechanisms. This architecture enabled faster training and better performance on various NLP tasks, leading to a new wave of state-of-the-art models.
- BERT (2018): Bidirectional Encoder Representations from Transformers (BERT) marked a major milestone in NLP. BERT is a pre-trained transformer model that can be fine-tuned for various tasks, such as sentiment analysis, named entity recognition, and question-answering. BERT achieved top performance across a wide range of benchmark datasets, demonstrating the effectiveness of transfer learning in NLP.
- GPT-2 and GPT-3 (2019, 2020): OpenAI’s Generative Pre-trained Transformers (GPT-2 and GPT-3) pushed the limits of language generation capabilities. GPT-3, in particular, showcased impressive performance on tasks like translation, summarization, and question-answering with minimal fine-tuning. GPT-3’s massive scale, with 175 billion parameters, highlighted the potential of large-scale language models.
- T5 (2019): The Text-to-Text Transfer Transformer (T5) model introduced a unified framework for various NLP tasks by converting them into a text-to-text format. This approach simplified the process of fine-tuning and adapting pre-trained models to different tasks.
During this period, NLP experienced rapid progress, with models becoming increasingly powerful and capable of understanding and generating human-like text. These advancements also sparked discussions on the ethical implications of such models and the need for responsible AI development.
From 2021 to 2023, NLP research and development continued to evolve rapidly. Here are some notable developments during this period:
- Large-scale Pre-trained Language Models (2021): The trend of training even larger and more powerful language models continued. These models, like OpenAI’s GPT-4, achieved impressive results across a wide range of NLP tasks. Researchers and developers started to build upon these models, exploring new ways to utilize and adapt them to different domains and applications.
- Efficient Language Models (2021-2023): As the size of language models increased, so did the computational requirements for training and deploying them. This led to a growing interest in developing more efficient models that balance performance and resource utilization. Techniques such as model distillation, pruning, and quantization became essential to create smaller, faster, and more energy-efficient models for practical deployment.
- Multimodal Models (2021-2023): Multimodal models, which can process and generate information across different modalities (e.g., text, images, and audio), gained traction. Models like OpenAI’s CLIP and DALL-E demonstrated the potential for leveraging pre-trained models to perform tasks that require understanding the relationship between text and images. Researchers continued to explore new architectures and training techniques for multimodal models.
- Ethics and Fairness in NLP (2021-2023): The increasing power and ubiquity of NLP models raised concerns about their ethical implications, such as potential biases, privacy issues, and the spread of misinformation. Researchers and developers started to prioritize fairness, accountability, and transparency, developing methods to mitigate biases, evaluate model fairness, and ensure responsible AI development.
- Domain-Specific and Low-Resource Language Models (2021-2023): Recognizing the limitations of large-scale models in handling domain-specific and low-resource language tasks, researchers began to focus on developing models tailored to specific domains and underrepresented languages. Techniques like data augmentation, transfer learning, and unsupervised learning were employed to improve performance on low-resource languages and specialized domains.
- Explainability and Interpretability (2021-2023): As NLP models became more complex, understanding their inner workings and decision-making processes became more challenging. Researchers started to explore new techniques for improving model explainability and interpretability, enabling users to better understand and trust the outputs generated by AI systems.
These are just a few of the many developments in NLP from 2021 to 2023. The field continued to evolve rapidly, with new architectures, algorithms, and applications emerging regularly, driving further innovation and growth in natural language processing.
1.2 Applications of NLP

There are numerous applications of NLP, some of which include:
- Sentiment Analysis: Determining the sentiment behind a piece of text, such as a positive, negative, or neutral sentiment in product reviews or social media posts.
- Machine Translation: Translating text from one language to another, like Google Translate.
- Text Summarization: Automatically generating a concise summary of a longer piece of text.
- Named Entity Recognition: Identifying and classifying entities in text, such as people, organizations, locations, and dates.
- Question Answering: Providing answers to natural language questions by understanding the context and extracting relevant information from a knowledge base or a given text.
- Speech Recognition: Converting spoken language into written text, used in voice assistants like Siri, Alexa, and Google Assistant.
- Chatbots: Conversational agents that can understand and respond to human language, used in customer support, e-commerce, and personal assistants.
1.3 Components of an NLP System
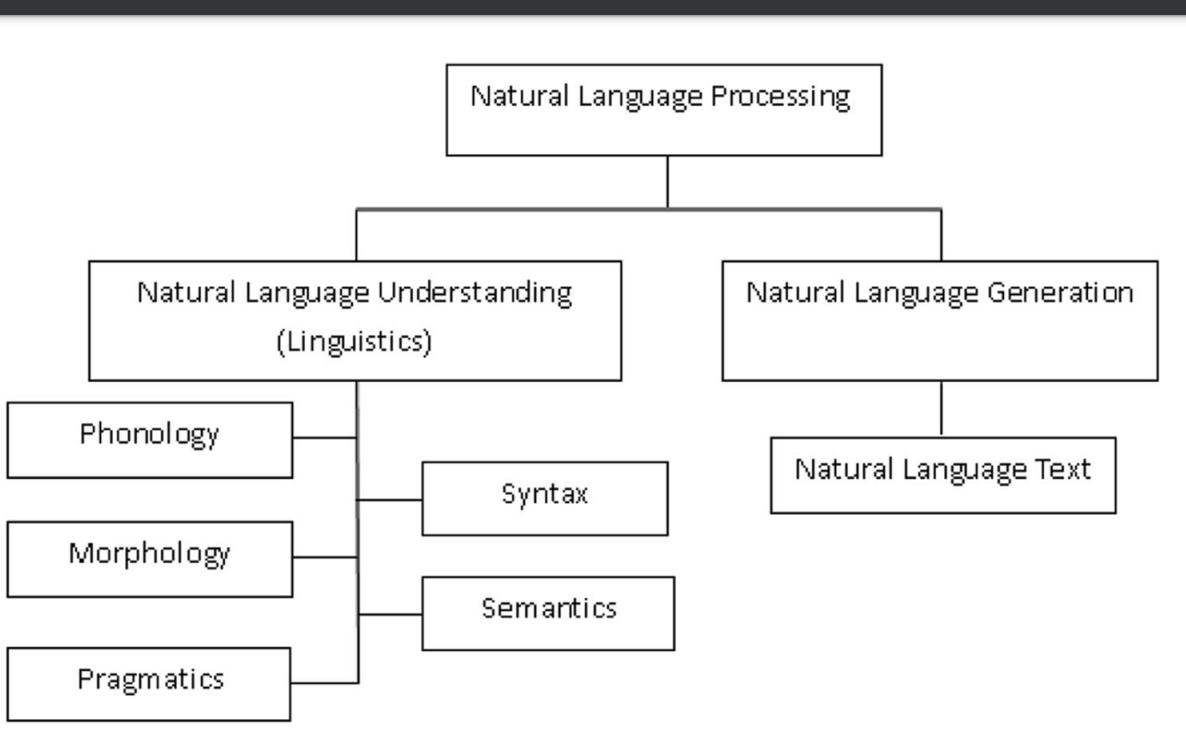
NLP can be broadly divided into two main components:
1. Natural Language Understanding (NLU)
2. Natural Language Generation (NLG)
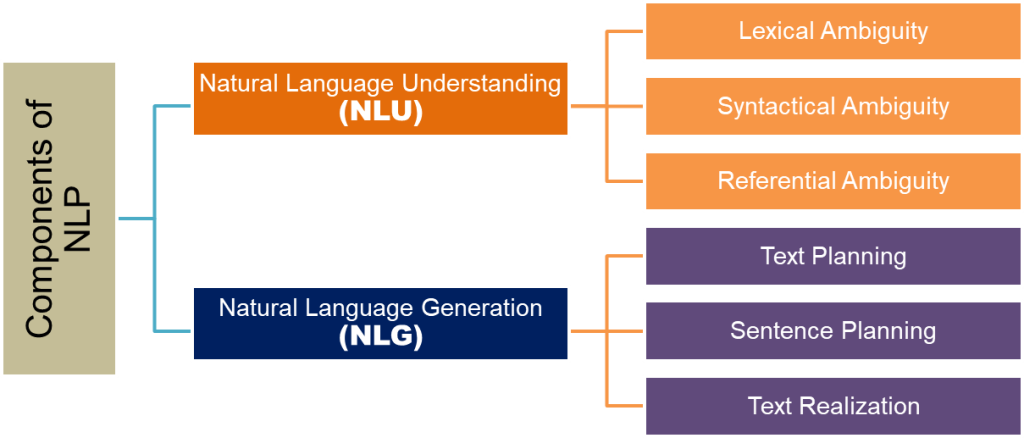
Natural Language Understanding (NLU):
NLU is the process of converting unstructured human language into structured data that a computer can understand and process. It involves extracting meaningful information and understanding the context of the text. The main tasks in NLU include:
Tokenization: Breaking down a text into individual words or tokens.
Part-of-speech tagging: Identifying the grammatical role of each word in the text, such as noun, verb, adjective, etc.
Named Entity Recognition: Identifying and categorizing entities such as people, organizations, dates, and locations within the text.
Sentiment Analysis: Determining the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral.
Dependency Parsing: Identifying the relationships between words in a sentence to understand the overall meaning.
Coreference Resolution: Identifying when two or more words refer to the same entity in the text.
Question Answering: Understanding and answering questions posed in natural language
Phonology
Phonology is a subfield of linguistics that deals with the systematic organization of sounds in a language. It focuses on the patterns and rules that govern how sounds, or phonemes, combine, and interact with one another to form meaningful units, such as words and sentences.
Phonology covers several key concepts, including:
Phonemes: Phonemes are the smallest units of sound that can distinguish one word from another in a language.
For example, in English, the sounds /p/ and /b/ are distinct phonemes because they can differentiate words like “pat” and “bat.”
Allophones: Allophones are the variations in the pronunciation of a phoneme that do not change a word’s meaning.
For instance, the English phoneme /t/ has different allophones depending on its position in a word, such as the aspirated [tʰ] in “top” or the flapped [ɾ] in “butter.”
Syllables: A syllable is a basic unit of speech that consists of a vowel sound and, optionally, consonant sounds that precede or follow it. Syllables play a crucial role in determining the rhythm and stress patterns of a language.
Phonotactics: Phonotactics refers to the rules that govern the combination and sequence of phonemes within a language. These rules determine which phonemes can appear together in a syllable or word, and in what order.
For example, in English, the cluster /st/ can appear at the beginning of a word (e.g., “stop”), but not at the end.
Prosody: Prosody encompasses the suprasegmental features of speech, such as stress, pitch, and intonation. These features help convey meaning, emphasis, and emotion in spoken language.
For example, the difference in meaning between the questions “You’re going to the store?” and the statement “You’re going to the store” lies in their prosody.
Assimilation and Coarticulation: Assimilation occurs when a sound changes its characteristics to resemble a neighboring sound, making speech production more efficient. Coarticulation is the simultaneous production of two or more sounds, influencing each other’s articulation.
For example, the /n/ in “input” is pronounced with the tongue at the alveolar ridge, while the /m/ in “impossible” is pronounced with the lips closed, due to the influence of the following /p/.
Phonology plays a crucial role in understanding spoken language and developing speech recognition systems, as well as in teaching and learning foreign languages. By analyzing the patterns and rules that govern a language’s sound system, researchers can gain insights into how sounds are organized and used to convey meaning in human communication.
Morphology
Morphology is the study of the structure and formation of words in a language. It deals with the internal organization of words, their components, and how these components combine to form meaningful units. In natural language processing, morphology plays a crucial role in understanding and processing text, as it helps in identifying the basic building blocks of words and their meanings.
Here are some key concepts in morphology:
Morphemes:A morpheme is the smallest meaningful unit in a language. Morphemes can be words themselves or parts of words that carry meaning or function. There are two types of morphemes:
Free morphemes: These morphemes can stand alone as words, e.g., ‘cat,’ ‘dog,’ and ‘run.’
Bound morphemes: These morphemes cannot stand alone and must be attached to other morphemes to convey meaning, e.g., the prefix ‘un-‘ in ‘undo’ or the suffix ‘-ed’ in ‘played.’
Inflection:Inflection is the process of modifying words to express different grammatical features, such as tense, number, gender, case, or mood. For example, in English, verbs can be inflected for tense (e.g., ‘play’ vs. ‘played’) and nouns for number (e.g., ‘cat’ vs. ‘cats’).
Derivation:Derivation is the process of creating new words by adding affixes (prefixes or suffixes) to existing words or morphemes. For example, adding the suffix ‘-ness’ to the adjective ‘happy’ results in the noun ‘happiness.’
Compounding:Compounding is the process of creating new words by combining two or more existing words. For example, ‘blackboard’ is a compound formed by combining the words ‘black’ and ‘board.’
In NLP, morphological analysis is an essential step in tasks such as tokenization, part-of-speech tagging, and stemming/lemmatization. It helps identify the root forms of words and their grammatical properties, which can improve the performance of language models and other NLP applications. Morphological analysis techniques can include rule-based methods, statistical models, and machine learning algorithms.
Syntax: on the other hand, applies the rules of a language’s grammar to determine the role of each word in a sentence and organizes this information into a structure that is easier to analyze further. English sentences typically consist of noun phrases, verb phrases, and sometimes prepositional phrases. These phrases help identify the sentence’s structure and meaning.
Grammar: is a set of rules governing the structure and composition of sentences in a language. In English, statements usually consist of various parts of speech, such as verbs, nouns, adjectives, adverbs, conjunctions, pronouns, and articles. These elements work together to create meaningful sentences.
Parsing: is the process of converting a sentence into a tree structure representing its syntactic structure. For example, the sentence “The green book is sitting on the desk” can be broken down into a noun phrase “The green book” and a verb phrase “is sitting on the desk.” The parsing process labels the articles, adjectives, nouns, and other elements in the sentence, ensuring that the sentence follows the language’s grammar rules.
In linguistics, the term “lexical” refers to aspects of language that relate to the lexicon, or vocabulary, of a language. The lexicon consists of all the words and word-like units, such as morphemes, that are available to speakers for constructing sentences and conveying meaning. The study of lexical aspects of language encompasses several sub-disciplines and topics, including:
Lexicology: Lexicology is the study of words, their structure, and their meanings. It explores the relationships between words, such as synonyms, antonyms, and homonyms, and investigates the various dimensions of meaning that words can have, including denotative meaning, connotative meaning, and figurative meaning.
Lexicography: Lexicography is the practice of compiling, writing, and editing dictionaries. Lexicographers collect, analyze, and organize information about words, their meanings, and their usage to create reference works that help people understand and use language more effectively.
Lexical semantics: Lexical semantics focuses on the meaning of individual words and the relationships between words. It investigates how words are organized into semantic fields or categories, how word meanings can change over time, and how meaning is influenced by factors such as context, speaker intention, and world knowledge.
Lexical morphology: Lexical morphology deals with the structure and formation of words. It studies how words are built from smaller units, called morphemes, and how these morphemes combine to form complex words or inflected forms.
Word formation: Word formation is the process by which new words are created in a language. It includes processes such as compounding (combining two or more words), derivation (adding affixes to existing words), and conversion (changing the grammatical category of a word without changing its form).
Lexical phonology: Lexical phonology examines the sound patterns and phonological processes that are specific to the lexicon. It investigates how the phonological structure of words can influence their meanings and how phonological processes can contribute to the formation and recognition of words.
Lexical pragmatics: Lexical pragmatics deals with the ways in which context, speaker intention, and shared knowledge influence the interpretation of words and their meanings. It studies how words can be used to convey meaning in different contexts and how they can be used to perform various speech acts, such as making requests, giving advice, or expressing emotions.
By studying the lexical aspects of language, linguists can gain a deeper understanding of how words function within a language system and how they contribute to the richness and complexity of human communication.
Syntactic analys
Syntactic analysis, also known as parsing or syntax analysis, is a crucial component of natural language processing and computational linguistics. It deals with the study of the rules governing the structure and arrangement of words in phrases and sentences. Syntactic analysis aims to identify the grammatical relationships among words in a sentence and build a hierarchical structure that represents the underlying syntactic organization.
Here are some key concepts in syntactic analysis:
Constituency: Constituency refers to the grouping of words in a sentence that function as a single unit. Constituents can be simple (e.g., a noun phrase) or complex (e.g., a clause). Syntactic analysis involves identifying constituents and determining their hierarchical organization within a sentence.
Phrase structure rules: Phrase structure rules are grammar rules that dictate the organization of words and phrases in a sentence. These rules are typically represented as a hierarchical tree structure, with each node in the tree corresponding to a constituent. For example, a simple phrase structure rule might be that a sentence (S) consists of a noun phrase (NP) followed by a verb phrase (VP).
Syntactic categories: Syntactic categories, also known as parts of speech or grammatical categories, are classes of words that share similar syntactic behavior. Common syntactic categories include nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunctions, and interjections. Syntactic analysis involves assigning words to their appropriate categories and determining their roles within the sentence structure.
Dependencies and relations: Dependency relations describe the grammatical relationships between words in a sentence. In a dependency-based approach to syntactic analysis, sentences are represented as directed graphs, with words as nodes and grammatical dependencies as edges. Examples of dependency relations include subject, object, and modifier relationships.
Parsing algorithms: Parsing algorithms are computational methods used to perform syntactic analysis on sentences. There are several types of parsing algorithms, including top-down, bottom-up, and chart parsing, as well as probabilistic and machine learning-based approaches. These algorithms aim to construct a parse tree or dependency graph that represents the underlying syntactic structure of a sentence.
Ambiguity and disambiguation: Syntactic ambiguity arises when a sentence can be parsed in multiple ways, resulting in different interpretations of its structure and meaning. Disambiguation is the process of selecting the most appropriate parse among the possible alternatives, often using context, semantic information, or statistical information to make an informed decision.
By understanding and analyzing the syntactic structure of sentences, NLP systems can more accurately interpret the meaning of text and perform tasks such as machine translation, information extraction, and sentiment analysis.
Semantics is a subfield of linguistics that focuses on the study of meaning in language. It investigates how words, phrases, sentences, and texts are used to convey meaning and how language users understand and interpret these meanings. Semantics is concerned with various aspects of meaning, including:
Lexical semantics: Lexical semantics is the study of the meaning of individual words and the relationships among them. It investigates word meaning, synonymy (words with similar meanings), antonymy (words with opposite meanings), hyponymy (words that are more specific in meaning), and meronymy (words that are part of a larger whole). Lexical semantics also deals with the study of polysemy (multiple meanings of a single word) and homonymy (different words with the same form).
Compositional semantics: Compositional semantics is the study of how meanings of individual words combine to form meanings of larger phrases and sentences. It seeks to understand how syntax and semantics interact to convey meaning in context. Compositional semantics often involves the use of formal tools and theories, such as predicate logic and lambda calculus, to represent and analyze meaning.
Truth-conditional semantics: Truth-conditional semantics is a theory of meaning that focuses on the conditions under which a sentence can be considered true or false. It assumes that the meaning of a sentence can be represented by the conditions that must hold for the sentence to be true. For example, the meaning of the sentence “The cat is on the mat” can be represented by the condition that there exists a cat and a mat, and the cat is located on the mat.
Reference and denotation: Reference is the relationship between linguistic expressions and the entities in the world to which they refer. Denotation is the set of entities in the world that a word or phrase refers to. Semantics studies how words and phrases can have reference and denotation, and how these relationships contribute to meaning.
Sense and reference: The philosopher Gottlob Frege made a distinction between sense and reference. Sense refers to the way in which a word or expression conveys meaning, while reference refers to the actual entity in the world that the word or expression refers to. Semantics investigates the relationship between sense and reference in language.
Context and meaning: Semantics also deals with the role of context in determining meaning. Context can include factors such as the physical environment, the speaker’s intentions, the listener’s background knowledge, and the linguistic context (the surrounding words and sentences). Semantics explores how context can influence the interpretation of meaning and resolve ambiguities.
Pragmatics and semantics: Pragmatics is another subfield of linguistics that deals with meaning, focusing on how language users convey and interpret meaning in context. Semantics and pragmatics often overlap and interact, as they both contribute to our understanding of meaning in language.
By studying semantics, linguists and researchers gain insights into how human language conveys meaning, how meaning is represented in the mind, and how language users understand and interpret meaning in various contexts.
Discourse is a subfield of linguistics that focuses on the study of language use beyond the sentence level, examining how sequences of utterances, written or spoken, come together to form cohesive and coherent texts or conversations. Discourse analysis investigates various aspects of language in context, such as the structure, function, and organization of texts or spoken interactions, as well as the social, cultural, and cognitive factors that influence their production and interpretation.
Some key aspects of discourse analysis include:
Cohesion: Cohesion refers to the grammatical and lexical features that create connections between different parts of a text or conversation, ensuring that the discourse flows smoothly and is easy to understand. Examples of cohesive devices include pronouns, conjunctions, and lexical repetition.
Coherence: Coherence refers to the overall sense of unity and logical organization in a discourse, ensuring that the ideas and information presented are connected, relevant, and easy to follow. Coherence is achieved through various means, such as logical organization, clear topic development, and the use of appropriate transitions.
Speech Acts: Discourse analysts study speech acts, which are the functional units of communication that convey meaning and perform actions through language. Examples of speech acts include questions, assertions, requests, promises, and apologies. Researchers examine how speech acts are used to achieve specific communicative goals and how they are affected by factors such as politeness and context.
Turn-taking: In spoken discourse, turn-taking refers to the process by which speakers alternate in taking the floor during a conversation. Discourse analysts investigate the rules and strategies that govern turn-taking, as well as the ways in which speakers negotiate and manage turns to ensure smooth and effective communication.
Conversation Analysis: Conversation analysis is a specific approach to discourse analysis that focuses on the detailed examination of the structure and organization of talk in everyday interactions. Researchers analyze recordings of naturally occurring conversations to uncover the implicit rules and patterns that govern conversational behavior, including turn-taking, topic management, and the use of repair strategies to resolve misunderstandings.
Critical Discourse Analysis: Critical discourse analysis (CDA) is an approach to discourse analysis that examines the ways in which language contributes to the construction and reproduction of social power relations, ideologies, and identities. CDA researchers analyze texts and spoken interactions to reveal the hidden assumptions and biases that shape the way people think and talk about social issues, such as race, gender, and class.
By studying discourse, linguists can gain insights into the social, cognitive, and cultural processes that underlie language use and contribute to the construction of meaning in context.
Pragmatics is a subfield of linguistics that deals with the study of how language is used in context to achieve specific goals or purposes. Pragmatics is concerned with the ways in which meaning is shaped by factors such as context, speaker intention, and shared knowledge between the speaker and listener. It goes beyond the literal meaning of words and phrases, focusing on how people use language to convey meaning, perform actions, and achieve desired effects on their listeners.
Some key aspects of pragmatics include:
Speech Acts: Speech acts are the actions performed by speakers through language. For example, making a request, giving an order, asking a question, or making a promise are all speech acts. Pragmatics explores how language is used to perform these various functions and how the listener interprets these intentions.
Implicature: Implicature refers to the additional meaning that a speaker intends to convey beyond the literal meaning of an utterance. For example, if a person says, “It’s cold in here,” they may be implying that they want someone to close the window or turn up the heat, even though they didn’t say so explicitly.
Deixis: Deixis deals with the way that language relies on context to provide meaning. Deictic expressions, such as pronouns (e.g., “he,” “she,” “it”), demonstratives (e.g., “this,” “that”), and adverbs of time and place (e.g., “here,” “there,” “now,” “then”), require contextual information to be fully understood.
Politeness: Politeness in pragmatics refers to the ways in which speakers use language to show respect, maintain social relationships, and avoid offense. Politeness strategies can include the use of indirect speech acts, hedges, and other linguistic devices to soften requests, criticisms, or other potentially face-threatening acts.
Presupposition: Presupposition involves the background assumptions or shared knowledge that speakers and listeners bring to a conversation. For example, if someone asks, “Did you enjoy the concert?”, it is presupposed that the person attended a concert. Pragmatics examines how presuppositions influence the interpretation of utterances and how they can be used strategically in communication.
Context: Pragmatics is heavily dependent on context, which includes the physical and social setting, the participants in the conversation, and the shared knowledge and beliefs of the speaker and listener. Context plays a crucial role in determining the meaning of an utterance and how it is understood by the listener.
In summary, pragmatics is a subfield of linguistics that focuses on the study of how language is used in context to convey meaning, perform actions, and achieve desired effects on listeners. It considers various factors, such as context, speaker intention, and shared knowledge, to understand how meaning is constructed and interpreted in communication.
Ambiguity in natural language refers to situations where a word, phrase, or sentence can have multiple possible meanings or interpretations. Ambiguity can arise at different levels of language processing, including lexical, syntactic, and semantic levels. Understanding and resolving ambiguity is an essential aspect of natural language processing.
Lexical ambiguity: Lexical ambiguity occurs when a single word has multiple meanings or senses. This type of ambiguity is also called homonymy or polysemy. For example, the word “bat” can refer to a flying mammal or a piece of sports equipment used in baseball. Context usually helps in disambiguating the intended meaning.
Syntactic ambiguity: Syntactic ambiguity, or structural ambiguity, arises when a sentence can be parsed in multiple ways due to its structure or grammar. This leads to different interpretations of the same sentence. For example, the sentence “I saw the man with the telescope” can be interpreted as either the speaker saw a man who had a telescope, or the speaker used a telescope to see the man.
Semantic ambiguity: Semantic ambiguity occurs when the meaning of a phrase or sentence is unclear, even if the individual words and grammar are unambiguous. This type of ambiguity is related to the broader context of the text or the knowledge of the reader or listener. For example, the sentence “He is looking for a match” can be ambiguous because it could mean that the person is searching for a suitable opponent in a game or sport, or it could mean that the person is searching for a small stick used to create a flame.
Resolving ambiguity in natural language processing often involves techniques such as:
Minimizing ambiguity: Simplifying or rephrasing the text to reduce the chances of ambiguity.
Preserving ambiguity: Retaining multiple interpretations and allowing the user or a downstream process to choose the most appropriate meaning based on context.
Interactive disambiguation: Engaging in a dialogue with the user to clarify the intended meaning of ambiguous expressions.
Weighting ambiguity: Assigning probabilities to different interpretations based on factors such as context, world knowledge, or prior experience, and choosing the most likely interpretation.
Ambiguity is an inherent aspect of human language, and addressing it effectively is a critical challenge for natural language processing and artificial intelligence systems.
Natural Language Generation (NLG):
NLG is the process of generating human language from structured data or information. It involves creating coherent and meaningful sentences, paragraphs, or even entire documents in a way that is similar to how humans write. The main tasks in NLG include:
Text Summarization: Creating a shorter version of a given text while preserving its essential information and meaning.
Machine Translation: Translating text from one language to another.
Paraphrasing: Generating a new version of a given text with the same meaning but different words.
Dialogue Generation: Generating responses or conversations in a dialogue system, such as chatbots or virtual assistants.
Content Generation: Creating human-like text, such as articles, stories, or reports, based on a given topic or set of information.
Natural Language Generation (NLG) is a subfield of Natural Language Processing (NLP) that focuses on creating coherent, meaningful, and human-like text from structured data or internal representations. The NLG process can be broken down into four main stages:
Identifying the goals: In this initial stage, the primary objective or purpose of the generated text is determined. This could include conveying specific information, answering a question, summarizing data, or persuading the reader. Understanding the goals helps to shape the content and structure of the generated text.
Planning: Once the goals are identified, the next step is to plan how to achieve them by evaluating the available data, context, and communicative resources. This involves organizing the information, selecting relevant details, and determining the overall structure and flow of the text. The planning stage may also include considering the target audience and adjusting the language, style, or tone accordingly.
Generating the text: After planning, the system generates the actual text based on the identified goals and planned structure. This process typically involves converting the internal representation of the information into natural language sentences. The system may use templates, rules, or machine learning models to construct the text, ensuring that it is grammatically correct and coherent.
Realizing the plans as a text: The final step involves refining the generated text to ensure it meets the desired quality, style, and coherence. This may include revising the text for clarity, conciseness, and readability, as well as checking for grammatical and syntactical correctness. The output should be a well-structured, meaningful, and easily understandable piece of text that effectively communicates the intended message or information.
Natural Language Generation plays a crucial role in various applications, such as chatbots, automated news generation, summarization, content generation, and more. Advances in machine learning and deep learning techniques have significantly improved the quality and capabilities of NLG systems, enabling them to generate increasingly human-like and contextually relevant text.
.

In the context of NLG, there are two primary components: the speaker and the generator.
a) Speaker: The speaker component is responsible for determining the message or content that needs to be conveyed. It takes into account the context, the goal of the communication, and the intended audience. The speaker’s role is to decide what information should be included in the generated output, and it may involve selecting relevant data, filtering out unnecessary information, or even deciding on the style or tone of the message.
b) Generator: The generator component is responsible for turning the speaker’s decisions and input data into a coherent and grammatically correct output in the form of text or speech. This involves structuring the content, selecting appropriate words and phrases, and ensuring that the output follows the rules of the target language. The generator may also need to consider various factors such as the desired level of formality, politeness, or other stylistic preferences.
Together, the speaker and generator components work in tandem to create meaningful and natural-sounding text or speech, making NLG systems valuable tools for various applications, such as chatbots, automated report generation, and text summarization.
In Natural Language Generation (NLG), various components and levels of representation are involved to transform the input data into a coherent and meaningful output in the form of text or speech. The process typically follows a series of stages to generate the desired output.
b) Components and Levels of Representation:
Content determination: This stage involves deciding what information should be included in the generated output. It requires the system to filter, select, and organize relevant data based on the context, communication goals, and audience.
Document or message planning: Once the content is determined, the next step is to plan the structure of the output. This involves organizing the content into a logical and coherent order, considering factors such as discourse relations, coherence, and cohesion. The result of this stage is a high-level representation of the content and its organization.
Microplanning: In this stage, the system makes more detailed decisions about how to express the content. This includes choosing the appropriate lexical items (words and phrases), determining the syntactic structure, and managing aspects like pronoun usage, aggregation, and referring expressions.
Surface realization: The final stage involves converting the abstract representation from the microplanning phase into a grammatically correct and well-formed output in the target language. This includes applying the rules of syntax, morphology, and punctuation to produce a readable and natural-sounding text or speech.
These components and levels of representation play a crucial role in the overall NLG process. By breaking down the generation process into these stages, NLG systems can more effectively produce outputs that are coherent, contextually appropriate, and adhering to the rules and nuances of the target language.
b) Components and Levels of Representation
The process of language generation involves several interwoven tasks that contribute to creating coherent and meaningful text or speech. These tasks include:
Content selection: This step involves selecting the information that should be included in the generated text. It may require removing or adding parts of the information units based on their relevance and importance in the context.
Textual organization: Once the content is selected, it needs to be organized according to the grammar rules of the target language. This organization involves ordering the information sequentially and in terms of linguistic relations, such as modification and dependency.
Linguistic resources: To support the realization of the content, appropriate linguistic resources must be chosen. These resources can include words, idioms, syntactic constructs, and other language-specific elements that contribute to the fluency and coherence of the generated text.
Realization: In the final step, the selected and organized linguistic resources are realized as actual text or voice output. This is the stage where the text or speech is generated and presented to the user.
c) Application or Speaker
In the context of Natural Language Generation, the application or speaker is responsible for maintaining a model of the situation and initiating the language generation process. The speaker does not actively participate in the language generation itself but plays a crucial role in setting the stage for the process.
The speaker stores the history, structures the content that is potentially relevant, and deploys a representation of what it knows about the situation. These elements form the basis for selecting a subset of propositions that the speaker wants to convey. The primary requirement is that the speaker must make sense of the situation, ensuring that the generated output is contextually appropriate and meaningful to the intended audience.
In the context of Natural Language Generation (NLG), applications refer to the various real-world use cases where NLG systems can be employed to generate human-like text or speech. The speaker, as mentioned before, is a component within the NLG system responsible for determining the message or content that needs to be conveyed. Here, we will discuss some applications where the speaker component plays a crucial role:
Chatbots and Conversational AI: Chatbots use NLG systems to generate responses that engage users in natural, human-like conversations. The speaker component helps determine the appropriate response based on the user’s input and the chatbot’s knowledge.
Automated Report Generation: NLG systems can be used to generate reports, summaries, or analyses from large datasets. The speaker component decides what information to include in the report, ensuring that it is relevant and meaningful to the intended audience.
Personalized Marketing: NLG can be used to create personalized marketing messages, tailoring the content to individual users based on their preferences, behaviors, or demographics. The speaker component helps determine the most relevant and engaging content for each user.
News Generation: NLG systems can automatically generate news articles based on structured data, such as sports scores or financial reports. The speaker component is responsible for selecting the most newsworthy information and presenting it in a coherent and engaging manner.
Language Translation: In machine translation systems, the speaker component can play a role in determining the best way to convey the meaning of the source text in the target language, taking into account factors such as idiomatic expressions and cultural nuances.
Text Summarization: NLG systems can automatically generate summaries of long documents or articles. The speaker component helps identify the most important information and ensures that the summary accurately reflects the main points of the original text.
These are just a few examples of applications where the speaker component within NLG systems plays a vital role in generating meaningful and contextually appropriate output.
1.4 Challenges in NLP
NLP faces several challenges due to the complex and ambiguous nature of human language:
- Ambiguity: Words can have multiple meanings depending on the context in which they are used. For example, the word “bank” can refer to a financial institution or the side of a river.
- Syntax and Parsing: The structure and grammar of sentences can be complex, making it difficult to parse and understand the relationships between words and phrases.
- Idiomatic Expressions: Languages are full of idioms, proverbs, and colloquialisms that are difficult for computers to understand and interpret.
- Sarcasm and Irony: Detecting sarcasm and irony in text is a difficult task, as it often relies on context and tone, which may not be easily conveyed in written form.
- Domain-Specific Language: Texts from specific domains, such as legal, medical, or technical texts, may contain jargon and terminology that require specialized knowledge to understand and process.
NLP Pipeline
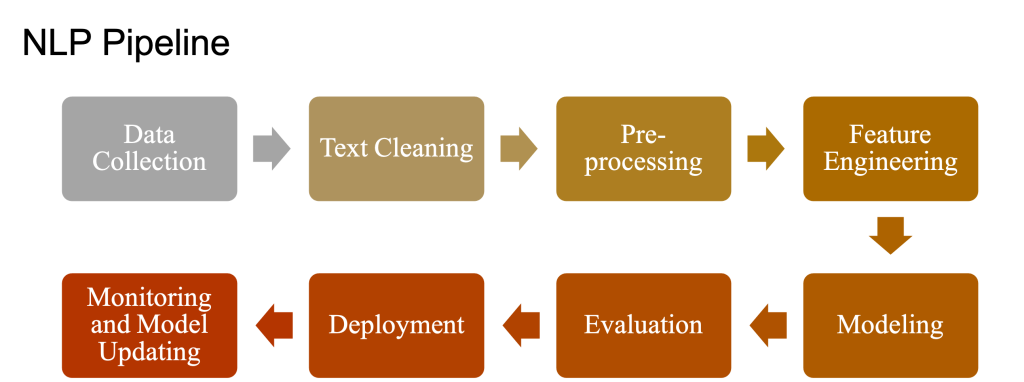
A Natural Language Processing (NLP) pipeline is a series of steps that transform raw text into structured data that can be used for various NLP tasks, such as sentiment analysis, text classification, or machine translation. Here’s a detailed explanation of a typical NLP pipeline with examples:
Text Preprocessing:
This step involves cleaning and preparing the raw text data for further analysis.
a. Lowercasing: Convert all text to lowercase to ensure consistency and reduce the dimensionality of the data.
Example: “Hello, World!” → “hello, world!”
b. Tokenization: Break down the text into individual words or tokens.
Example: “hello, world!” → [“hello”, “,”, “world”, “!”]
c. Stopword Removal: Remove common words that don’t contribute much to the meaning of the text, such as “and,” “the,” and “is.”
Example: [“hello”, “,”, “world”, “!”] → [“hello”, “,”, “world”, “!”]
d. Punctuation and Special Character Removal: Remove punctuation marks and special characters that are not relevant to the analysis.
Example: [“hello”, “,”, “world”, “!”] → [“hello”, “world”]
e. Stemming and Lemmatization: Reduce words to their base or root form to further reduce dimensionality and improve analysis.
Example: [“running”, “jumps”] → [“run”, “jump”]
Feature Extraction:
Transform the preprocessed text into a numerical representation that can be used as input for machine learning models.
a. Bag of Words (BoW): Represent the text as a frequency count of words present in the text.
Example: “hello world world” → {“hello”: 1, “world”: 2}
b. Term Frequency-Inverse Document Frequency (TF-IDF): Represent the text by considering the importance of words in the document and across the entire dataset.
Example: Given a set of documents, the TF-IDF value of a word is higher if it occurs frequently in a single document but is rare across all documents.
c. Word Embeddings: Represent words as high-dimensional vectors that capture semantic information and relationships between words.
Example: Word2Vec, GloVe, or FastText embeddings.
Model Training:
Train a machine learning model using the numerical representation of the text.
a. Choose an appropriate model, such as Naive Bayes, Support Vector Machines, or deep learning models like LSTM or Transformer-based models.
b. Split the data into training and validation sets to evaluate the model’s performance during training.
c. Train the model using the feature vectors and corresponding labels (e.g., sentiment labels or document categories).
Model Evaluation:
Assess the performance of the trained model using metrics such as accuracy, precision, recall, and F1-score.
Model Deployment and Inference:
Deploy the trained model to a production environment and use it to make predictions on new, unseen text data.
a. Preprocess the new text data following the same steps as during training.
b. Transform the preprocessed text into numerical features using the same feature extraction method.
c. Use the trained model to make predictions or generate output based on the transformed features.
This is a general overview of a typical NLP pipeline. The specific steps and techniques may vary depending on the task and requirements of the project.
Phases of NLP
What are the 5 steps in NLP?

Here are the five main phases of Natural Language Processing (NLP) with detailed explanations and examples:
- Lexical Analysis: The first phase in NLP is breaking down the input text into a sequence of tokens or words. This process is called tokenization. During lexical analysis, the text is also cleaned and preprocessed.
Example: Input text: “John’s car is very fast.” Tokens: [“John”, “‘s”, “car”, “is”, “very”, “fast”, “.”]
- Syntactic Analysis (Parsing): In this phase, the relationships between tokens are identified, and a syntactic structure (typically a parse tree) is generated based on the grammar rules of the language. This helps in understanding the grammatical structure of the text.
Example: Using a context-free grammar (CFG) for English, a parse tree might look like this for the sentence “The cat is on the mat.”
[S]
____|____
| |
[NP] [VP]
| |
[Det N] [V PP]
| | | _|_
The cat is [P NP]
on | |
Det N
the mat
- Semantic Analysis: Semantic analysis focuses on understanding the meaning of words, phrases, and sentences. In this phase, the goal is to extract meaning by resolving ambiguities, understanding references, and identifying word senses.
Example: Disambiguating word sense in the sentence “I went to the bank to deposit money.” Here, the word “bank” refers to a financial institution, not the side of a river.
- Discourse Integration: This phase aims to understand the context of the text by analyzing the text’s coherence and cohesion. It involves connecting sentences, understanding anaphora (pronoun references), and interpreting the overall context of the text.
Example: Text: “John went to the store. He bought some apples.” In this example, the pronoun “He” refers to “John.” Understanding this connection is part of discourse integration.
- Pragmatic Analysis: In the final phase, the goal is to interpret the intended meaning of the text by considering the context, the speaker’s intent, and real-world knowledge.
Example: A person asks, “Can you pass the salt?” The pragmatic meaning of this sentence is a request to pass the salt, not a question about the person’s ability to pass the salt.
These five phases form the foundation of NLP and provide a framework for analyzing and processing human language. The specific methods and techniques used in each phase may vary depending on the task and the desired outcome.
NLP Libraies

There are several popular NLP libraries that provide implementations of various NLP tasks and algorithms. Here’s a detailed overview of some widely-used NLP libraries:
- NLTK (Natural Language Toolkit): NLTK is a comprehensive Python library for natural language processing. It provides easy-to-use interfaces to over 50 corpora and lexical resources. Some key features include tokenization, stemming, lemmatization, POS tagging, parsing, and semantic reasoning.
- SpaCy: SpaCy is another popular Python library for advanced natural language processing tasks. It’s designed specifically for production use and provides fast and efficient implementations of various NLP tasks. Some notable features include tokenization, POS tagging, named entity recognition (NER), dependency parsing, and word vectors.
- Gensim: Gensim is a Python library for topic modeling, document similarity analysis, and word vector training. It’s designed to handle large text collections and is optimized for memory efficiency and speed. Some key features include implementations of Word2Vec, Doc2Vec, FastText, and Latent Semantic Analysis (LSA).
- Stanford CoreNLP: Stanford CoreNLP is a Java-based NLP library developed by the Stanford NLP Group. It provides a wide range of NLP tools, including tokenization, POS tagging, NER, sentiment analysis, and parsing. It also supports multiple languages and can be easily integrated with other programming languages via APIs.
- TextBlob: TextBlob is a simple Python library for processing textual data. It provides a simple API for common NLP tasks like part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
- Transformers (by Hugging Face): Transformers is a state-of-the-art Python library for natural language understanding and generation. It provides easy access to pre-trained transformer models like BERT, GPT-2, RoBERTa, and T5. The library supports various NLP tasks like text classification, named entity recognition, text generation, and question answering.
- OpenNLP (Apache OpenNLP): OpenNLP is a Java-based NLP library developed by the Apache Software Foundation. It provides various NLP tasks, including tokenization, sentence segmentation, POS tagging, named entity recognition, parsing, and more. OpenNLP also offers a flexible and extensible architecture, allowing developers to create custom NLP components.
These libraries provide a wide range of functionalities and tools for natural language processing. Depending on your specific needs and preferences, you can choose one or more of these libraries to help you with your NLP projects.